Artificial Intelligence and Machine Learning in Cybersecurity
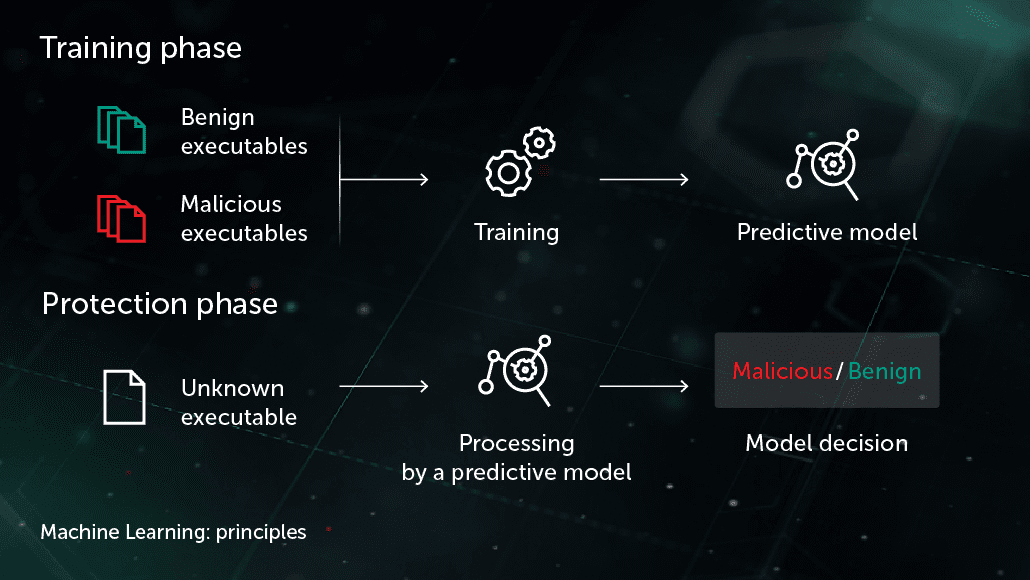
Arthur Samuel, a pioneer in artificial intelligence, described AI as a set of methods and technologies that “gives computers the ability to learn without being explicitly programmed.” In a particular case of supervised learning for anti-malware, the task could be formulated as follows: given a set of object features \( X \) and corresponding object labels \( Y \) as an input, create a model that will produce the correct labels \( Y' \) for previously unseen test objects \( X' \). \( X \) could be some features representing file content or behavior (file statistics, list of used API functions, etc.) and labels \( Y \) could be simply “malware” or “benign” (in more complex cases, we could be interested in a fine-grained classification such as Virus, Trojan-Downloader, Adware, etc.). In the case of unsupervised learning, we are more interested in revealing hidden structures within the data—e.g. finding groups of similar objects or highly correlated features.
Kaspersky’s multi-layered, next-generation protection uses approaches of AI such as ML extensively at all stages of the detection pipeline—from scalable clustering methods used for preprocessing incoming file streams to robust and compact deep neural network models for behavioral detection that work directly on users’ machines. These technologies are designed to address several important requirements for real-world cybersecurity applications, including an extremely low false positive rate, interpretability of models, and robustness against adversaries.
Let’s consider some of the most important ML-based technologies used in Kaspersky’s endpoint products:
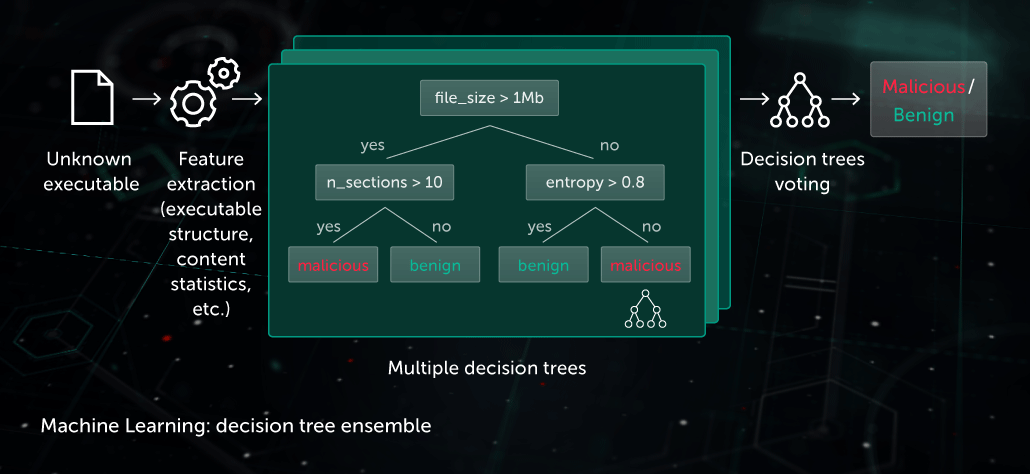
Decision Tree Ensemble
In this approach, the predictive model takes the form of a set of decision trees (e.g. random forest or gradient boosted trees). Every non-leaf node of a tree contains a question regarding features of a file, while the leaf nodes contain the final decision of the tree on the object. During the test phase, the model traverses the tree by answering the questions in the nodes with the corresponding features of the object under consideration. At the final stage, decisions of multiple trees are averaged in an algorithm-specific way to provide a final decision on the object.
The model benefits the Pre-Execution Proactive protection stage on the endpoint site. One of our applications of this technology is Cloud ML for Android used for mobile threat detection.
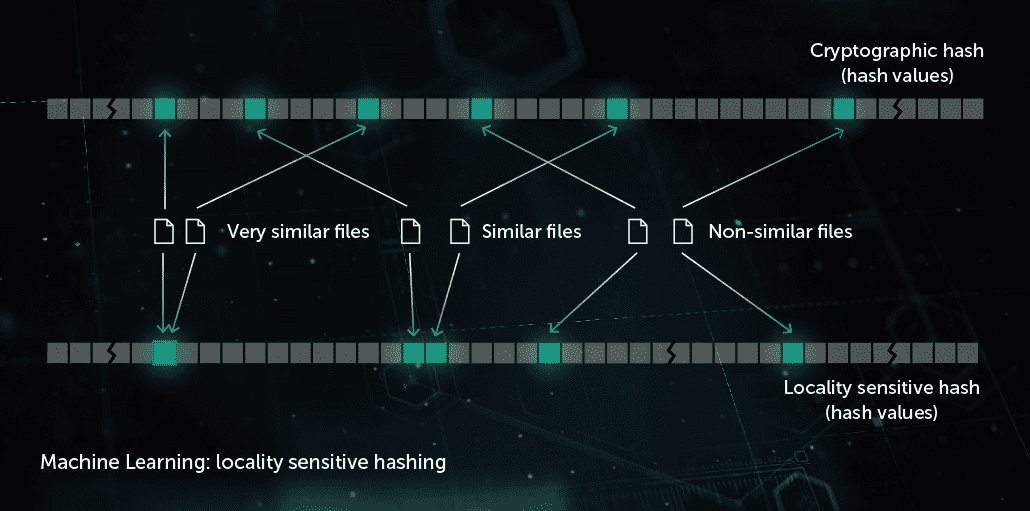
Similarity Hashing (Locality Sensitive Hashing)
In the past, hashes used to create malware “footprints” were sensitive to every small change in a file. This drawback was exploited by malware writers through obfuscation techniques like server-side polymorphism: minor changes in malware took it off the radar. Similarity hash (or locality sensitive hash) is an AI method to detect similar malicious files. To do this, the system extracts file features and uses orthogonal projection learning to choose the most important features. ML-based compression is then applied so that value vectors of similar features are transformed into similar or identical patterns. This method provides good generalization and noticeably reduces the size of the detection record base, since one record now can detect the whole family of polymorphic malware.
The model benefits the Pre-Execution Proactive protection stage on the endpoint site. It’s applied in our Similarity Hash Detection System.
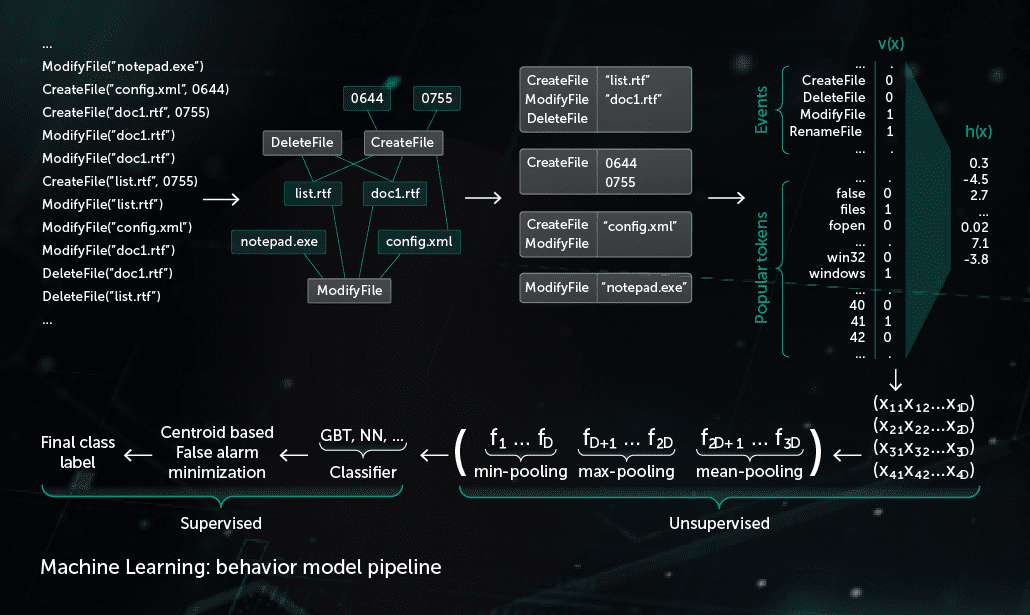
Behavioral Model
A monitoring component provides a behavior log—the sequence of system events occurring during the process execution together with corresponding arguments. To detect malicious activity in observed log data, our model compresses the obtained sequence of events into a set of binary vectors and trains the deep neural network to distinguish clean from malicious logs.
The object classification made by the Behavioral Model is used by both static and dynamic detection modules in Kaspersky products on the endpoint side.
AI also plays an equally important role in building proper in-lab malware processing infrastructure. Kaspersky uses it for the following infrastructure purposes:
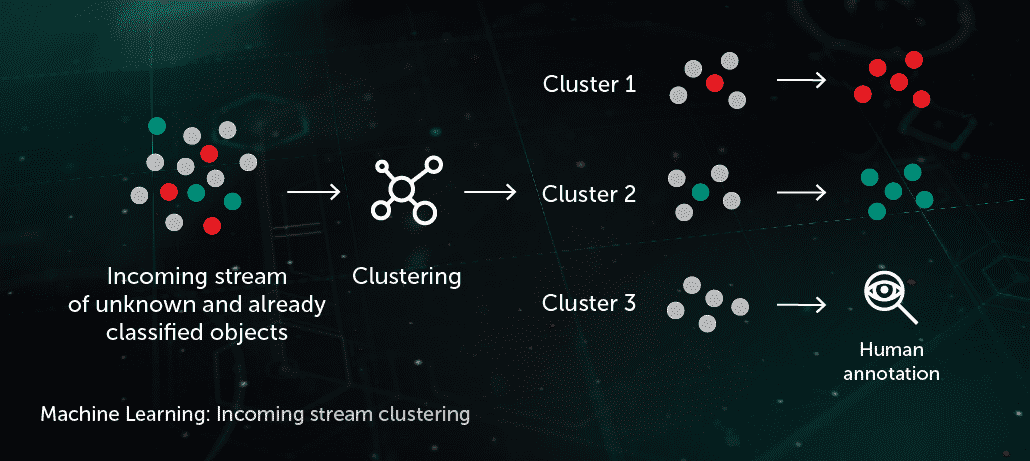
Incoming Stream Clustering
ML-based clustering algorithms allow us to efficiently separate the large volumes of unknown files coming to our infrastructure into a reasonable number of clusters, some of which can be automatically processed based on the presence of an already annotated object inside it.
Large-Scale Classification Models
Some of the most powerful classification models (like a huge random decision forest) require significant resources (processor time, memory) along with expensive feature extractors (e.g. processing via sandbox could be required for detailed behavior logs). It is more effective, therefore, to keep and run the models in a lab, and then distill the knowledge gained by these models via training some lightweight classification model on the output decisions of the bigger model.
Security in the use of ML aspects of AI
ML algorithms, once released from the confines of the lab into the real world, could be vulnerable to many forms of attacks designed to force AI systems into making deliberate errors. An attacker can poison a training dataset or reverse-engineer the model's code. Besides, hackers can ‘brute-force’ ML models with the help of specially developed ‘adversarial AI’ systems to automatically generate many attacking samples and launch them against the protective solution or extracted ML model until a weak point of the model is discovered. The impact of such attacks on anti-malware systems that use AI could be devastating: a misidentified Trojan means millions of devices infected and millions of dollars lost.
For this reason, there are some key considerations to apply when using AI in security systems:
- The security vendor should understand and carefully address essential requirements for the performance of AI elements in the real, potentially hostile world—requirements that include robustness against potential adversaries. ML/AI-specific security audits and ‘red-teaming’ should be key components in the development of security systems using aspects of AI.
- When assessing the security of a solution that uses elements of AI, ask to what degree the solution depends on third-party data and architectures, as many attacks are based on third-party input (we’re talking threat intelligence feeds, public datasets, pre-trained, and outsourced AI models).
- ML/AI methods should not be viewed as a silver bullet – they need to be part of a multi-layered security approach, where complementary protection technologies and human expertise work together, watching each other's backs.
It’s important to recognize that while Kaspersky has extensive experience in the efficient use of aspects of AI aspects such as ML and its Deep Learning subset in its cybersecurity solutions, these technologies are not true AI, or Artificial General Intelligence (AGI). There is still a long way to go until machines can operate independently and perform most tasks entirely autonomously. Until then, nearly every aspect of AI in cybersecurity will require the guidance and expertise of human professionals to develop and refine the systems, growing their capabilities over time.
For a more detailed overview of popular attacks on ML/AI algorithms and the methods of protection from these threats, read our whitepaper, "AI under Attack: How to Secure Artificial Intelligence in Security Systems".





